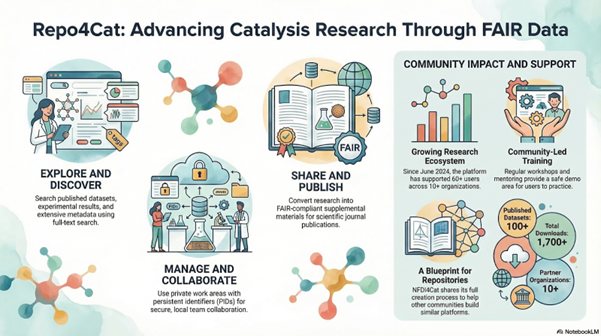
Repo4Cat is a central platform (repository) within the NFDI4Cat infrastructure where research can be stored, shared, published, discovered, and advanced collaboratively. Its success story is about user experience, from the first click and to the final publication of data.
The first interaction with the repository starts for the users with searching and exploring of already published datasets from the fields of catalysis:
- Real data from experiments as supplemental materials to scientific papers (input and configuration files, results of experiments, etc.)
- Original materials from the research projects (white papers, dissemination and training materials, etc.)
- Extensive metadata, history of changes and full text search inside of stored files
As next step users can create an account and start to use Repo4Cat for their own data – at first for storage and indexing of local catalogs:
- Long-term storage and management of research data, independent of locality or openness of research – even without publication data continues to be FAIR
- Work and collaboration on a local level possible, e.g., only within own organization or research group and even without publication – working areas with custom access rights, metadata and data storage possible
- Unique persistent identifiers (PIDs) for datasets and files – reference of data on a permanent way during the whole project life circle
And finally, the data in Repo4Cat can be properly shared and published:
- Storage, sharing and publication of research data using proper metadata and licenses – to make data truly FAIR
- Possibility to extend scientific publications in journals with real data from the experiments – using Repo4Cat to create supplemental materials to scientific papers, already during submission or peer-review
- Thanks PIDs published data stays accessible for a long term
Repo4Cat has been in operation since June 2024. After almost 2 years it has more than 60 users and more than 10 organizations, it represents 100+ published datasets with a total of 1700+ downloads.
Repo4Cat was created by and for the community. That’s why user support and training stay always in a central position – a special collection of repository guidelines and exercises helps users to make the first steps, and regular Repo4Cat workshops allow users to try the repository and discover its full functionality in a safe demo area and under the individual mentoring of the community experts.
Creation of a repository is not a trivial task, it includes many steps and takes some time. NFDI4Cat has collected all experience of Repo4Cat creation in one paper – from collection of requirements, comparison of the repository software products, to the installation process, operation of the repository and user support. This paper can be a starting point for other communities, who also plan to create their own repository. Additionally, NFDI4Cat shares its approach in the user training and in the user communication, which also can be reused by other communities.
Repo4Cat – let`s collect Catalysis data together!
- Find Repo4Cat
- Repository Guidelines and Exercises
- Find Demo Repo4Cat
- More info can be found in RDM School of Catalysis
- Find Repo4Cat creation paper
- User Training
- User Communication
Other posts
Posts
Humanities@NFDI: Working Together for Sustainable Research Data
Cross-Disciplinary Collaboration for Preserving Cultural Heritage
Humanities@NFDI brings together four NFDI consortia to ensure the long-term accessibility and reuse of research data in the humanities and cultural sciences. Through shared standards, vocabularies, and community-driven activities, the initiative fosters interdisciplinary collaboration and strengthens digital cultural heritage research.
QualidataNet by KonsortSWD-NFDI4Society is the “central point of entry” for qualitative data and its secondary use.
QualidataNet – Making Qualitative Research Data Visible and Reusable
QualidataNet is the central access point for the reuse, archiving, and research data management of qualitative research data. Its search portal improves the visibility and discoverability of qualitative datasets from different providers. Through practical guidance, tools such as the open-source anonymization tool QualiAnon, and contributions to international metadata standards, QualidataNet supports researchers, educators, and institutions working with qualitative data. At the same time, the network fosters collaboration, exchange, and a stronger culture of qualitative data reuse across the community.
Forum4MICA – Making Information Commonly Available (KonsortSWD I NFDI4Society)
Forum4MICA – Making Research Data Knowledge Accessible Together
Forum4MICA connects researchers and research data centers on one central platform. It provides a space to ask questions, exchange expertise, and discuss complex datasets from the social, behavioral, educational, and economic sciences. Through direct interaction with experts and the research community, the platform is building a sustainable knowledge archive for research data management and scientific collaboration.

Recent Comments