Fictional texts are severely underrepresented in major German reference corpora due to the high costs associated with licensing and data preparation. With DeLiKo-XL@DNB, Text+ offers a potential way out of this dilemma. In this initiative, the German National Library (DNB), in collaboration with the Leibniz Institute for the German Language (IDS), is making a large collection available for research for the first time.
With 287,585 fictional publications, the corpus includes all German-language fiction e-books published in EPUB format between 2012 and 2024, as well as all 362 digitally available titles that have ever been nominated for the German Book Prize. In total, the corpus comprises 20.9 billion tokens (words and punctuation marks).
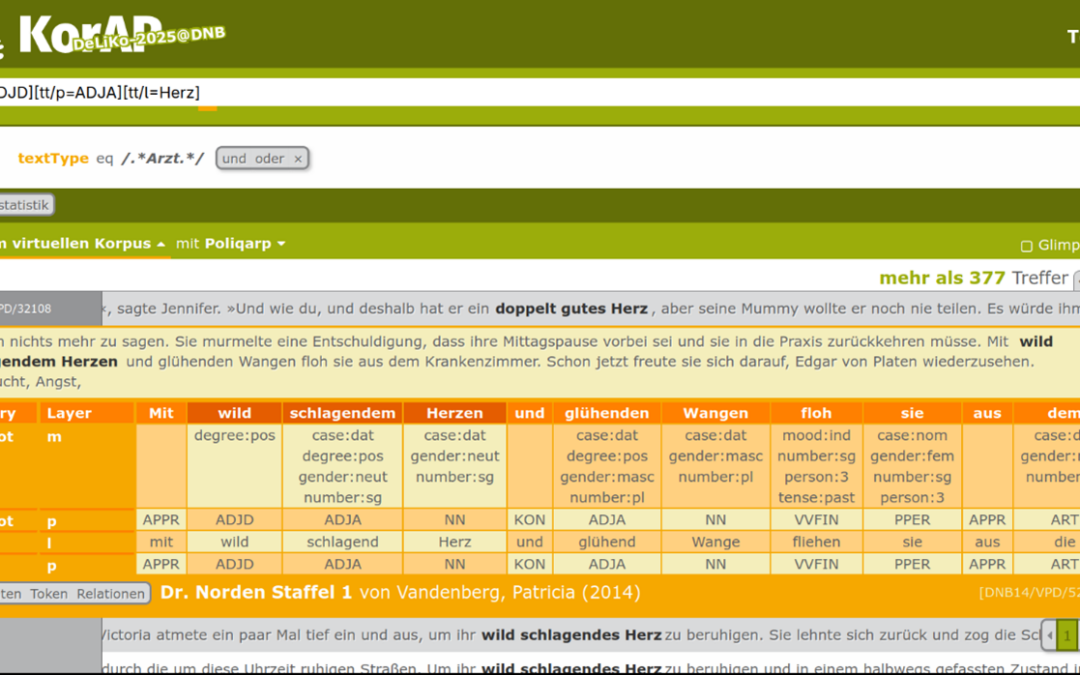
The corpus can be explored and analysed in a variety of ways using the corpus analysis platform KorAP. For example, users can flexibly create virtual subcorpora based on metadata, work with multi-layer annotations, and perform complex search queries in six query languages (including CQP). A query assistant supports users in formulating search queries, while a query-by-example function enables the identification of complex constructions based on example patterns. For practical use, R and Python libraries as well as video tutorials provided by the University of Mannheim offer an accessible starting point.
This access has been made possible by the introduction of the German copyright provision §60d UrhG, which permits text and data mining for scientific purposes. On this legal basis, and under the condition that the full texts, their annotations, and the KorAP instance remain within the infrastructure of the German National Library, researchers can freely search and analyse the corpus online without registration. The only limitation is that the context displayed for each search result is restricted to 50 words.
ZumTo the DeLiKo corpus:
KorAP source code:
Other Posts
Posts
Humanities@NFDI: Working Together for Sustainable Research Data
Cross-Disciplinary Collaboration for Preserving Cultural Heritage
Humanities@NFDI brings together four NFDI consortia to ensure the long-term accessibility and reuse of research data in the humanities and cultural sciences. Through shared standards, vocabularies, and community-driven activities, the initiative fosters interdisciplinary collaboration and strengthens digital cultural heritage research.
QualidataNet by KonsortSWD-NFDI4Society is the “central point of entry” for qualitative data and its secondary use.
QualidataNet – Making Qualitative Research Data Visible and Reusable
QualidataNet is the central access point for the reuse, archiving, and research data management of qualitative research data. Its search portal improves the visibility and discoverability of qualitative datasets from different providers. Through practical guidance, tools such as the open-source anonymization tool QualiAnon, and contributions to international metadata standards, QualidataNet supports researchers, educators, and institutions working with qualitative data. At the same time, the network fosters collaboration, exchange, and a stronger culture of qualitative data reuse across the community.
Forum4MICA – Making Information Commonly Available (KonsortSWD I NFDI4Society)
Forum4MICA – Making Research Data Knowledge Accessible Together
Forum4MICA connects researchers and research data centers on one central platform. It provides a space to ask questions, exchange expertise, and discuss complex datasets from the social, behavioral, educational, and economic sciences. Through direct interaction with experts and the research community, the platform is building a sustainable knowledge archive for research data management and scientific collaboration.

Recent Comments