
Fiktionale Texte sind aufgrund hoher Lizenz- und Aufbereitungskosten in den gängigen deutschen Referenzkorpora stark unterrepräsentiert. Text+ schafft mit DeLiKo-XL@DNB einen möglichen Ausweg aus diesem Dilemma. Darin erschließt die Deutsche Nationalbibliothek (DNB) zusammen mit dem Leibniz-Institut für Deutsche Sprache (IDS) erstmals einen umfangreichen Bestand für die Forschung.
Mit 287 585 fiktionalen Publikationen umfasst das Korpus alle deutschen im EPUB-Format veröffentlichten belletristischen E-Books zwischen 2012 und 2024 sowie alle 362 digital verfügbaren Titel, die jemals für den Deutschen Buchpreis nominiert waren – insgesamt sind das 20,9 Milliarden Token (Wörter und Satzzeichen).
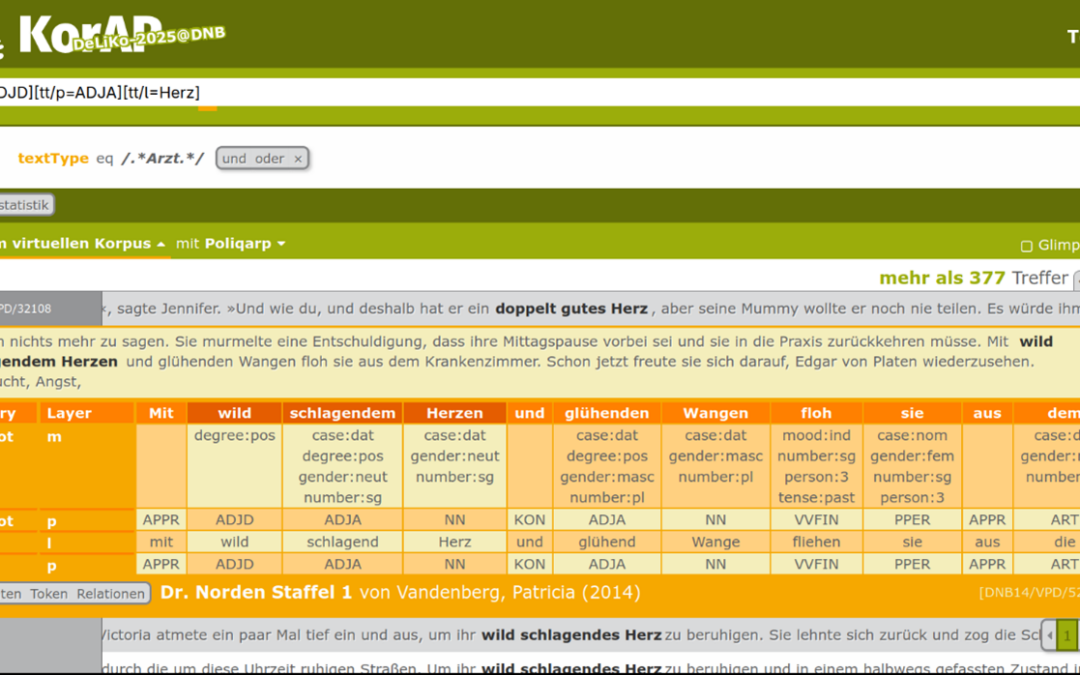
Mit der Korpus-Analyseplattform KorAP kann das Korpus auf vielfältige Weise genutzt werden. Möglich sind zum Beispiel die flexible, metadatenbasierte Erstellung virtueller Unterkorpora, mehrschichtige Annotationen, komplexe Suchanfragen in sechs Sprachen (u. a. CQP). Dabei unterstützt ein Anfrage Assistent das Formulieren von Suchanfragen und eine Query by Example-Funktion das Auffinden komplexer Konstruktionen anhand von Beispielen. Für die praktische Anwendung bieten R- und Python-Bibliotheken sowie Video-Tutorials der Universität Mannheim einen niederschwelligen Einstieg.
Möglich wurde diese Nutzbarmachung durch die Einführung der Urheberrechtsschranke §60d UrhG, die Text-und-Data-Mining zu wissenschaftlichen Zwecken erlaubt. Auf dieser rechtlichen Grundlage und unter der Voraussetzung, dass die Volltexte, deren Annotation und die KorAP-Instanz stets in der Infrastruktur der DNB verbleiben, können Forschende ohne Anmeldung das Korpus frei und online durchsuchen und analysieren. Die einzige Einschränkung ist ein Kontext von 50 Wörtern pro Suchtreffer.
Zum DeLiKo-Korpus:
KorAP-Quellcode:
Andere Beiträge
Humanities@NFDI: Gemeinsam für nachhaltige Forschungsdaten
Fächerübergreifende Kooperation für den Erhalt des kulturellen Erbes
Die Humanities@NFDI-Initiative vereint vier NFDI-Konsortien, um Forschungsdaten aus den Geistes- und Kulturwissenschaften nachhaltig zugänglich und nachnutzbar zu machen. Durch gemeinsame Standards, Vokabulare und Community-Formate stärkt die Zusammenarbeit die Vernetzung und schafft die Grundlage für interdisziplinäre Forschung.
QualidataNet von KonsortSWD-NFDI4Society ist der „central point of entry“ für qualitative Daten und ihre Nachnachnutzung
QualidataNet – Gemeinsam qualitative Forschungsdaten sichtbar und nutzbar machen
QualidataNet ist der zentrale Zugangspunkt für die Nachnutzung, Archivierung und das Forschungsdatenmanagement qualitativer Forschungsdaten. Über das Suchportal werden qualitative Daten verschiedener Anbieter sichtbar und auffindbar gemacht. Mit praxisnahen Handreichungen, Tools wie dem Open-Source-Anonymisierungstool QualiAnon sowie internationaler Standardisierungsarbeit unterstützt QualidataNet Forschende, Lehrende und Institutionen im Umgang mit qualitativen Daten. Gleichzeitig stärkt das Netzwerk Austausch, Kooperation und die Kultur der Datennachnutzung innerhalb der Community.
Forum4MICA – Making Information Commonly Available (KonsortSWD I NFDI4Society)
Forum4MICA – Wissen zu Forschungsdaten gemeinsam zugänglich machen
Forum4MICA bündelt Informationen zu Forschungsdaten aus den Sozial-, Verhaltens-, Bildungs- und Wirtschaftswissenschaften auf einer zentralen Plattform. Forschende können dort Fragen zu komplexen Datensätzen stellen, Antworten von Expert:innen aus Forschungsdatenzentren erhalten und sich mit der Community austauschen. So entsteht ein nachhaltiges Wissensarchiv für Forschungsdatenmanagement und wissenschaftliche Vernetzung.

Recent Comments